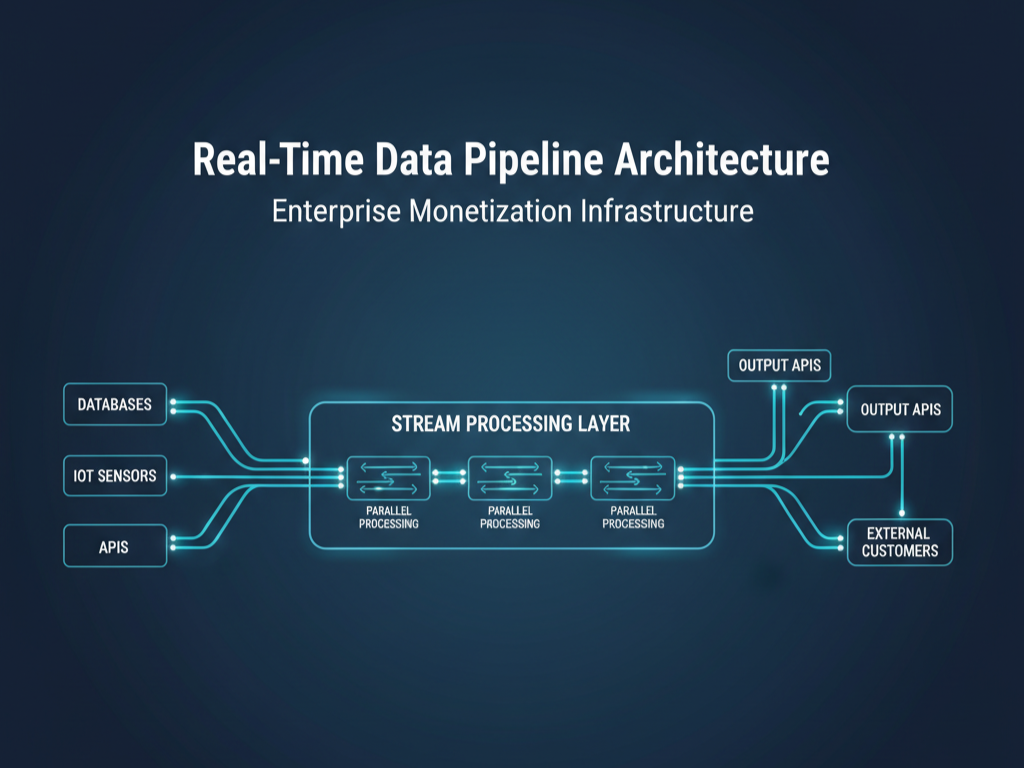
Your customer data platform might be collecting terabytes of valuable information, but if you can’t process and deliver that data in real-time, you’re missing the highest-value monetization opportunities. While batch processing sufficed for internal reporting, today’s data buyers expect immediate insights, predictive alerts, and live data feeds.
The difference between a $50,000 annual data licensing deal and a $500,000 recurring revenue stream often comes down to one thing: infrastructure that can deliver data products in real-time.
After architecting data monetization platforms for enterprises handling everything from IoT sensor networks to financial transaction streams, we’ve learned that successful data monetization requires more than clean data—it requires infrastructure designed specifically for external consumption, not just internal analytics.
The Real-Time Monetization Imperative
Market Reality Check
The data monetization market has reached $4.15 billion in 2024 and is projected to grow to $41.25 billion by 2034—a 25.81% compound annual growth rate, according to Precedence Research. But here’s what most technical leaders miss: the highest-value segment of this market isn’t historical data sales.
It’s real-time data streams.
API monetization models command premium pricing:
- Real-time API calls: $0.50-$5.00 per query
- Batch data exports: $0.05-$0.25 per record
- Live streaming subscriptions: $10,000-$100,000 monthly
- Historical data dumps: $25,000-$100,000 one-time
The infrastructure requirements for these different monetization models are fundamentally different. You can’t retrofit a batch processing system to deliver real-time value.
The Technical Debt Problem
Most enterprise data architectures were built for internal consumption with these characteristics:
- Batch processing optimized for throughput, not latency
- ETL pipelines designed for overnight processing windows
- Data warehouses structured for analytical queries, not operational APIs
- Security models built for internal users, not external customers
This creates what we call “monetization technical debt”—infrastructure that actively prevents you from capturing the highest-value opportunities in the data economy. Unlike the forecasting challenges that cost enterprises $2.5 trillion annually, infrastructure problems can be solved systematically with the right architectural approach.
Core Architecture Principles for Data Monetization
1. Stream-First Design Philosophy
Traditional enterprise data architecture follows an ETL (Extract, Transform, Load) pattern optimized for analytical workloads. Data monetization requires an ELT (Extract, Load, Transform) approach with stream processing at its core.
Stream Processing vs. Batch Processing for Monetization:
| Capability | Batch Processing | Stream Processing |
|---|---|---|
| Latency | Hours to days | Milliseconds to seconds |
| Monetization Model | One-time sales | Recurring subscriptions |
| Customer Value | Historical insights | Predictive alerts |
| Pricing Power | Commodity | Premium |
| Infrastructure Cost | Lower | Higher initially, better ROI |
Implementation Pattern:
Data Sources → Stream Ingestion → Real-time Processing → API Layer → External Customers
↓ ↓ ↓ ↓
Historical → Batch Processing → Data Warehouse → Internal Analytics
2. API-First Data Product Design
Your data products need to be designed as APIs from the ground up, not databases with an API wrapper. This means thinking about:
Schema Design for External Consumption:
- Consistent, versioned data schemas
- Backward compatibility guarantees
- Self-documenting API endpoints
- Rate limiting and usage analytics built-in
Example Schema Evolution Strategy:
{
"api_version": "2.1",
"data_schema_version": "1.3",
"backward_compatible_until": "2.0",
"response": {
"customer_journey_insights": [...],
"metadata": {
"confidence_score": 0.94,
"data_freshness": "real-time",
"geographic_coverage": ["US", "CA", "EU"]
}
}
}
3. Multi-Tenant Security Architecture
Data monetization means serving external customers with different security requirements, compliance needs, and data access levels. Your architecture must support:
- Tenant isolation at the data and compute level
- Dynamic access controls based on subscription tiers
- Audit trails for compliance and billing
- Data residency controls for international customers
Stream Processing Implementation for Enterprise Scale
Apache Kafka as the Backbone
For enterprises handling significant data volumes, Apache Kafka provides the foundation for real-time data monetization:
Configuration for Monetization Workloads:
# High-throughput, low-latency configuration
num.network.threads: 8
num.io.threads: 16
socket.send.buffer.bytes: 102400
socket.receive.buffer.bytes: 102400
socket.request.max.bytes: 104857600
# Durability for customer SLAs
default.replication.factor: 3
min.insync.replicas: 2
unclean.leader.election.enable: false
# Retention for data product requirements
log.retention.hours: 168 # 7 days for real-time products
log.retention.bytes: 1073741824 # 1GB per partition
Topic Design Pattern for Data Products:
customer-behavior-events-v2
├── partition-0 (geographic: US-West)
├── partition-1 (geographic: US-East)
├── partition-2 (geographic: EU)
└── partition-3 (geographic: APAC)
transaction-insights-enriched-v1
├── partition-0 (tier: premium-customers)
├── partition-1 (tier: standard-customers)
└── partition-2 (tier: trial-customers)
Stream Processing with Apache Flink
While Kafka handles ingestion and distribution, Apache Flink excels at complex event processing required for high-value data products:
Real-World Implementation Example:
// Customer journey pattern detection for retail monetization
val customerEvents = env.addSource(new FlinkKafkaConsumer[CustomerEvent](...))
val journeyPatterns = customerEvents
.keyBy(_.customerId)
.window(SlidingEventTimeWindows.of(Time.hours(24), Time.minutes(15)))
.apply(new PatternDetectionFunction())
.filter(pattern => pattern.confidence > 0.8)
.map(pattern => JourneyInsight(
pattern.customerId,
pattern.predictedNextAction,
pattern.confidence,
pattern.valueScore
))
journeyPatterns.addSink(new FlinkKafkaProducer[JourneyInsight](...))
This pattern enables real-time customer journey insights that retail companies can monetize through:
- Predictive analytics APIs
- Real-time personalization services
- Cross-sell/upsell optimization tools
Alternative: Cloud-Native Stream Processing
For organizations preferring managed services, cloud providers offer sophisticated stream processing capabilities:
Google Cloud Dataflow Example:
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
def process_transaction_data(element):
# Real-time fraud scoring for financial data monetization
transaction = json.loads(element)
fraud_score = calculate_fraud_probability(transaction)
return {
'transaction_id': transaction['id'],
'fraud_score': fraud_score,
'risk_level': categorize_risk(fraud_score),
'timestamp': time.time()
}
with beam.Pipeline(options=PipelineOptions()) as pipeline:
(pipeline
| 'Read from Pub/Sub' >> beam.io.ReadFromPubSub(subscription=subscription_path)
| 'Process Transactions' >> beam.Map(process_transaction_data)
| 'Write to BigQuery' >> beam.io.WriteToBigQuery(
table='fraud_insights',
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
API Gateway Architecture for Data Monetization
Rate Limiting and Tiered Access
Your API gateway must support sophisticated access controls that align with your monetization model:
Kong Gateway Configuration Example:
services:
- name: customer-insights-api
url: http://data-processing-service:8080
plugins:
- name: rate-limiting-advanced
config:
limit:
- 1000 # Premium tier: 1000 requests/hour
- 100 # Standard tier: 100 requests/hour
- 10 # Trial tier: 10 requests/hour
window_size: [3600]
identifier: consumer
sync_rate: 10
- name: request-size-limiting
config:
allowed_payload_size: 1024
- name: response-transformer
config:
add:
headers:
- "X-Data-Freshness: real-time"
- "X-API-Version: 2.1"
Authentication and Authorization
External data customers require enterprise-grade security:
OAuth 2.0 + JWT Implementation:
// Token validation middleware for data API access
const validateDataAccess = async (req, res, next) => {
try {
const token = req.headers.authorization?.split(' ')[1];
const decoded = jwt.verify(token, process.env.JWT_SECRET);
// Check subscription tier and data access permissions
const customer = await Customer.findById(decoded.customerId);
const hasAccess = await checkDataProductAccess(
customer.subscriptionTier,
req.params.dataProduct
);
if (!hasAccess) {
return res.status(403).json({
error: 'Insufficient subscription tier for requested data product'
});
}
req.customer = customer;
next();
} catch (error) {
res.status(401).json({ error: 'Invalid or expired token' });
}
};
Usage Analytics and Billing Integration
Real-time usage tracking enables sophisticated billing models:
Usage Tracking Implementation:
import redis
import json
from datetime import datetime, timedelta
class UsageTracker:
def __init__(self, redis_client):
self.redis = redis_client
def track_api_call(self, customer_id, endpoint, response_size):
# Track for real-time rate limiting
minute_key = f"usage:{customer_id}:{datetime.now().strftime('%Y%m%d%H%M')}"
self.redis.incr(minute_key)
self.redis.expire(minute_key, 3600) # 1 hour TTL
# Track for billing
daily_key = f"billing:{customer_id}:{datetime.now().strftime('%Y%m%d')}"
usage_data = {
'endpoint': endpoint,
'timestamp': datetime.now().isoformat(),
'response_size_bytes': response_size,
'billing_units': calculate_billing_units(endpoint, response_size)
}
self.redis.lpush(daily_key, json.dumps(usage_data))
self.redis.expire(daily_key, 86400 * 90) # 90 days retention
Data Quality and SLA Management
Real-Time Data Quality Monitoring
External customers have zero tolerance for data quality issues. Implement continuous monitoring:
Great Expectations Integration:
import great_expectations as ge
from great_expectations.core import ExpectationSuite
def create_data_product_expectations():
suite = ExpectationSuite("customer_insights_api_v2")
# Data freshness expectations
suite.add_expectation({
"expectation_type": "expect_column_max_to_be_between",
"kwargs": {
"column": "data_timestamp",
"min_value": (datetime.now() - timedelta(minutes=5)).timestamp(),
"max_value": datetime.now().timestamp()
}
})
# Data completeness expectations
suite.add_expectation({
"expectation_type": "expect_column_values_to_not_be_null",
"kwargs": {"column": "customer_id"}
})
# Business rule expectations
suite.add_expectation({
"expectation_type": "expect_column_values_to_be_between",
"kwargs": {
"column": "confidence_score",
"min_value": 0.0,
"max_value": 1.0
}
})
return suite
# Real-time validation in stream processing
def validate_data_quality(data_batch):
df = pd.DataFrame(data_batch)
results = ge.from_pandas(df).validate(
expectation_suite=create_data_product_expectations()
)
if not results.success:
# Alert on data quality issues
send_data_quality_alert(results.result_format)
# Potentially halt data delivery to customers
return False
return True
SLA Monitoring and Alerting
Implement comprehensive SLA monitoring for external data customers:
Prometheus + Grafana Monitoring Stack:
# Prometheus configuration for data API monitoring
- job_name: 'data-api-monitoring'
static_configs:
- targets: ['api-gateway:8080']
metrics_path: /metrics
scrape_interval: 15s
# Custom metrics for SLA monitoring
metric_relabel_configs:
- source_labels: [__name__]
regex: 'http_request_duration_seconds.*'
target_label: __name__
replacement: 'data_api_latency'
- source_labels: [__name__]
regex: 'http_requests_total.*'
target_label: __name__
replacement: 'data_api_requests'
SLA Alert Rules:
groups:
- name: data_monetization_slas
rules:
- alert: DataAPIHighLatency
expr: histogram_quantile(0.95, data_api_latency) > 0.5
for: 2m
labels:
severity: warning
customer_impact: high
annotations:
summary: "Data API 95th percentile latency above SLA"
- alert: DataFreshnessViolation
expr: (time() - max(data_timestamp)) > 300 # 5 minutes
for: 1m
labels:
severity: critical
customer_impact: critical
annotations:
summary: "Data freshness SLA violated"
Scaling and Performance Optimization
Horizontal Scaling Patterns
Design your architecture for elastic scaling based on customer demand:
Kubernetes Deployment for Stream Processing:
apiVersion: apps/v1
kind: Deployment
metadata:
name: stream-processor
spec:
replicas: 3
selector:
matchLabels:
app: stream-processor
template:
metadata:
labels:
app: stream-processor
spec:
containers:
- name: flink-taskmanager
image: flink:1.17
resources:
requests:
memory: "2Gi"
cpu: "1000m"
limits:
memory: "4Gi"
cpu: "2000m"
env:
- name: FLINK_PROPERTIES
value: |
taskmanager.numberOfTaskSlots: 4
taskmanager.memory.process.size: 3g
state.backend: rocksdb
state.checkpoints.dir: s3://data-monetization/checkpoints
---
apiVersion: v1
kind: Service
metadata:
name: stream-processor-service
spec:
selector:
app: stream-processor
ports:
- port: 8081
targetPort: 8081
type: LoadBalancer
Caching Strategy for High-Frequency Access
Implement intelligent caching to reduce infrastructure costs while maintaining performance:
Redis Caching Layer:
import redis
import json
import hashlib
from datetime import timedelta
class DataProductCache:
def __init__(self, redis_client):
self.redis = redis_client
self.default_ttl = 300 # 5 minutes for real-time data
def get_cached_result(self, query_params, customer_tier):
# Generate cache key based on query and customer tier
cache_key = self._generate_cache_key(query_params, customer_tier)
cached_result = self.redis.get(cache_key)
if cached_result:
return json.loads(cached_result)
return None
def cache_result(self, query_params, customer_tier, result):
cache_key = self._generate_cache_key(query_params, customer_tier)
# Shorter TTL for premium customers (fresher data)
ttl = 60 if customer_tier == 'premium' else self.default_ttl
self.redis.setex(
cache_key,
ttl,
json.dumps(result, default=str)
)
def _generate_cache_key(self, query_params, customer_tier):
query_string = json.dumps(query_params, sort_keys=True)
hash_key = hashlib.md5(f"{query_string}:{customer_tier}".encode()).hexdigest()
return f"data_product:{hash_key}"
Cost Optimization and Resource Management
Infrastructure Cost vs. Revenue Optimization
Balance infrastructure costs against monetization revenue:
Cost Monitoring Implementation:
import boto3
from datetime import datetime, timedelta
class InfrastructureCostOptimizer:
def __init__(self):
self.cloudwatch = boto3.client('cloudwatch')
self.cost_explorer = boto3.client('ce')
def calculate_customer_infrastructure_cost(self, customer_id, date_range):
# Calculate infrastructure cost per customer
api_calls = self._get_customer_api_usage(customer_id, date_range)
processing_cost = api_calls * 0.0001 # $0.0001 per API call
data_transfer = self._get_customer_data_transfer(customer_id, date_range)
transfer_cost = data_transfer * 0.09 # $0.09 per GB
storage_cost = self._calculate_customer_storage_cost(customer_id)
return {
'total_cost': processing_cost + transfer_cost + storage_cost,
'processing_cost': processing_cost,
'transfer_cost': transfer_cost,
'storage_cost': storage_cost,
'cost_per_api_call': (processing_cost + transfer_cost) / max(api_calls, 1)
}
def optimize_resource_allocation(self):
# Automatic scaling based on cost efficiency
high_cost_customers = self._identify_high_cost_customers()
for customer in high_cost_customers:
if customer.cost_per_call > customer.revenue_per_call * 0.7:
# Suggest tier upgrade or usage optimization
self._suggest_tier_optimization(customer)
Implementation Roadmap
Phase 1: Foundation (Weeks 1-4)
- Week 1-2: Stream processing infrastructure setup (Kafka, Flink/Cloud alternative)
- Week 3-4: API gateway implementation with basic authentication
Phase 2: Data Products (Weeks 5-8)
- Week 5-6: First data product development and testing
- Week 7-8: Usage tracking and billing integration
Phase 3: Scale and Optimize (Weeks 9-12)
- Week 9-10: SLA monitoring and alerting implementation
- Week 11-12: Performance optimization and cost management
Phase 4: Advanced Features (Weeks 13-16)
- Week 13-14: Multi-tenant security enhancement
- Week 15-16: Advanced analytics and customer success features
Common Implementation Pitfalls
1. Underestimating Security Requirements
External data customers require enterprise-grade security. Don’t retrofit security—design it in from the beginning. Learn more about compliance-first data monetization strategies.
2. Ignoring Data Freshness Requirements
Different data products have different freshness requirements. Real-time fraud detection needs sub-second latency; market research insights can tolerate 15-minute delays.
3. Over-Engineering for Scale
Start with proven technologies that can scale. Don’t build a system for 1 million API calls when you’re serving 1,000. Focus on avoiding the common data monetization mistakes that lead to over-investment in infrastructure.
4. Inadequate Usage Monitoring
Without detailed usage analytics, you can’t optimize pricing, detect abuse, or provide customer success.
Measuring Success
Technical KPIs
- API latency: 95th percentile under 500ms
- Data freshness: 99% of data delivered within SLA
- System availability: 99.9% uptime
- Data quality: Less than 0.1% error rate
Business KPIs
- API utilization rate: Percentage of subscribed capacity used
- Customer churn rate: Monthly customer retention
- Revenue per API call: Improving unit economics
- Cost per customer: Infrastructure efficiency
Conclusion
Building enterprise-grade data monetization infrastructure requires more than connecting APIs to databases. It demands a fundamental shift from internal-focused data architecture to customer-centric data products.
The companies capturing the highest value in the $41.25 billion data monetization market aren’t just selling data—they’re delivering data experiences that justify premium pricing through superior infrastructure.
Success comes from treating your data products like mission-critical services, because for your customers, they are.
Ready to build your data monetization infrastructure? The technologies exist, the market demand is proven, and the revenue opportunity is massive. The question isn’t whether to build real-time data products—it’s whether you’ll build them before your competitors do.
Schedule a free data infrastructure assessment to discover how much revenue your current data could generate with the right architecture.
About BINOBAN: We help enterprises unlock millions in revenue from their existing data assets through proven monetization strategies and technical implementation expertise. Get your custom data monetization assessment to discover your specific opportunities.